OrchTech
协律科技
开放场景中的通用移动操作基座
让机器人与环境、与人协律而行
Confidential
请输入机构专属访问密码,验证通过后5分钟内无需重复输入。
开放场景中的通用移动操作基座
让机器人与环境、与人协律而行
下一代具身技术核心命题
Manipulation
Mobile + Manipulation
分步拼接 ≠ 开放空间移动操作
Mobile Manipulation
面对无法穷举的交互对象与复杂的交互顺序,高节拍稳定移动操作依赖对场景演化的理解,现有的依靠示教数据的模仿学习范式(VLA & WAM)无法让机器人真正迈向开放场景。
团队在高动力学交互任务中具备顶尖系统设计以及工程部署经验,适配真实需求场景
相关学术成果在机器人顶刊发表并获得 IROS 移动操作最佳论文,覆盖移动操作、全身协同控制与人形整机开放场景执行验证
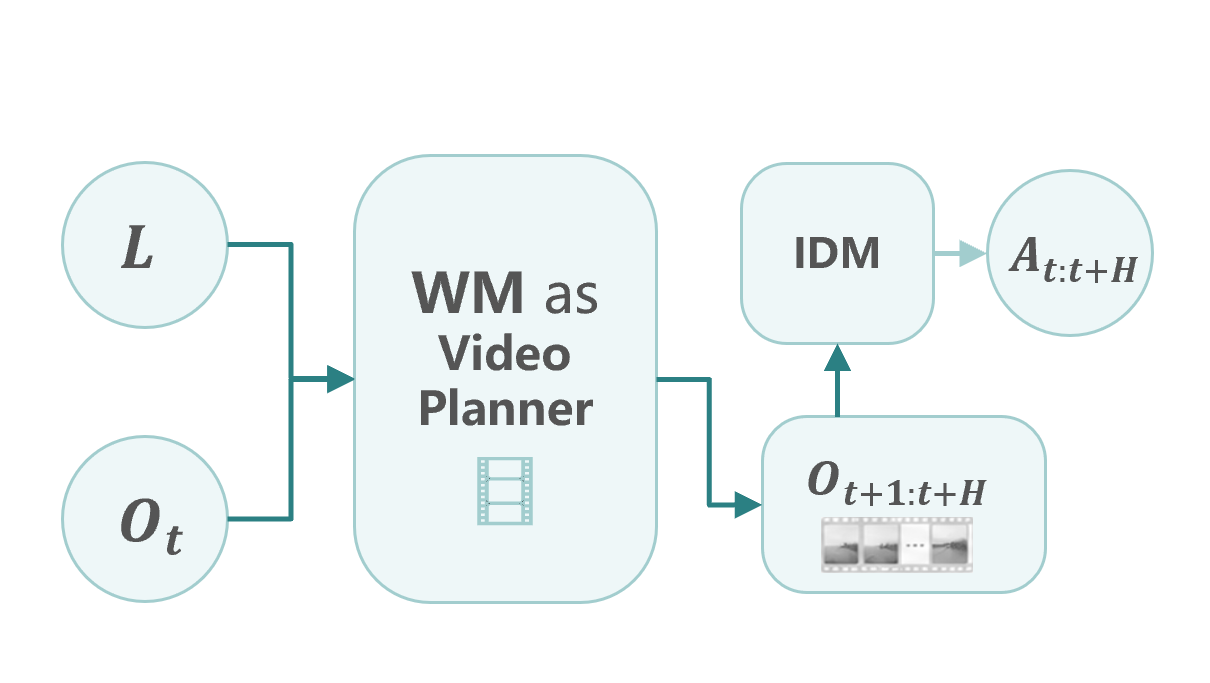
作为视频规划器与逆动力学模型(IDM)联合使用,由渲染预测的未来视觉状态反推可行动作,常用于灵巧手操作。
依靠大量专家数据覆盖任务分布,端到端生成动作,跳过机器人"感知-预测-规划-执行"闭环系统的中间环节,适用于固定场景固定任务。
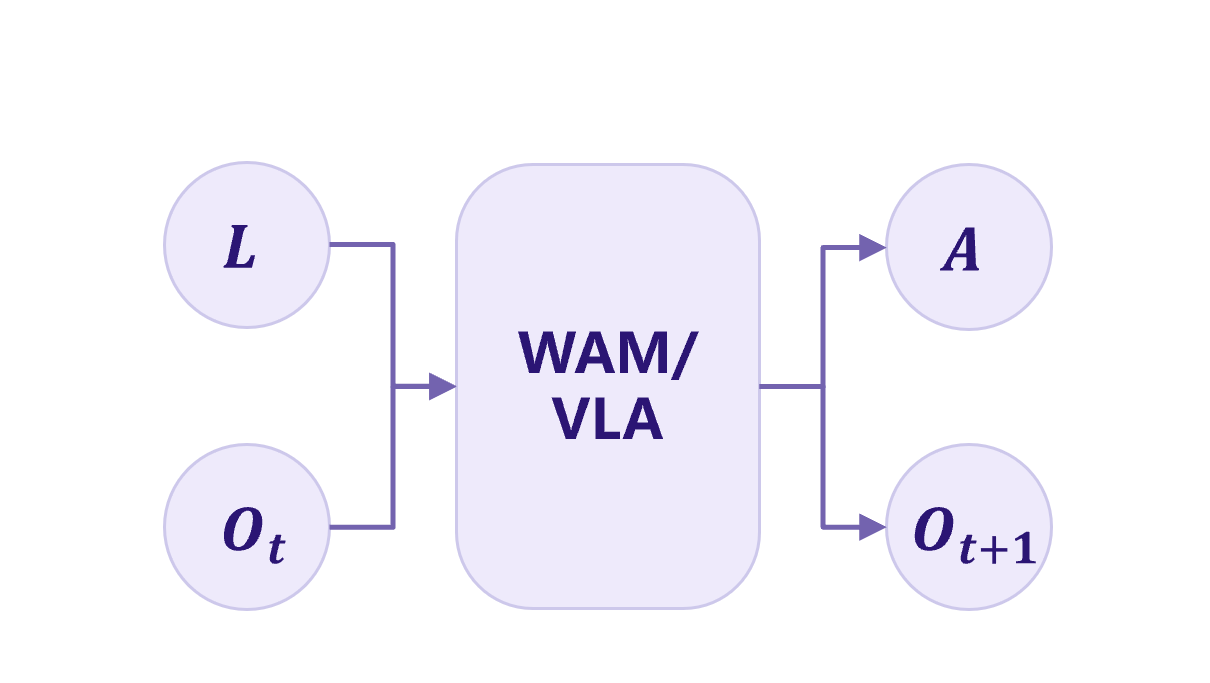
基于 JEPA 的隐空间状态预测器 + 规划架构,预测器层理解不同动作下交互状态如何演化,规划层基于预测结果规划最优动作并完成闭环执行。
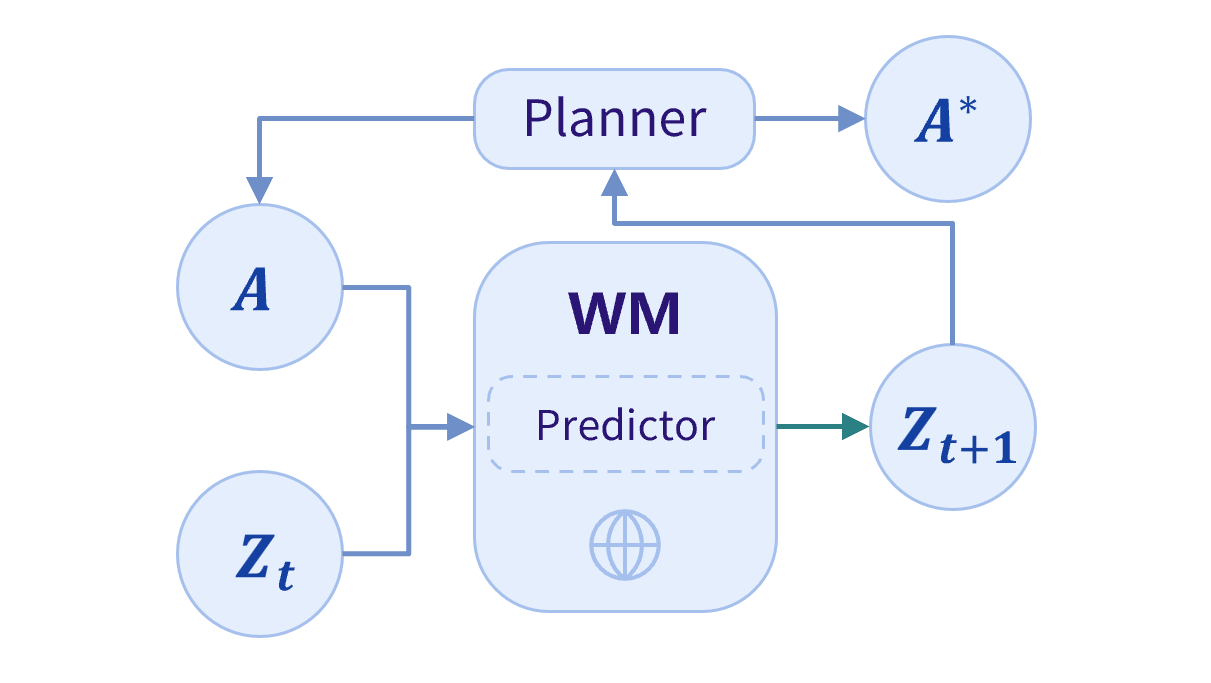
★ 拆分预测器和规划控制器,兼顾机器人在复杂任务中系统级高频鲁棒闭环规划执行能力与Model作为预测器的的跨场景推演能力
港科 Robotics 核心班底,兼具顶级研究与整机研发能力
哈佛大学访问学者 · 新国立博后 · 港科大博士 · 加州大学圣地亚哥硕士
移动操作 · 交互式接触及导航 · 物理仿真器 · 隐空间推理世界模型
港科大博士后&博士 · 中科院大学硕士 · 戴盟联创 & 小鹏
开放场景定位导航 · 复杂环境感知 · 全身运控 · 整机部署
港大博士 · 港科大硕士 · 上海 AI Lab
具身智能与生成式模型负责人
视觉语言操作 · 开放词汇导航 · 强化学习 · 世界模型
Google Scholar 引用 900+
港科大博士 · 哥大硕士 · 逐际动力
轮腿机器人 · 可重构底盘 · 人形下肢 · 移动操作整机运控
港科大博后&博士 · UCB访问学者 · 普渡硕士 · 上交本科
自动驾驶多机决策与规划 · 自主决策 · 安全交互
普渡机器人产品研发 · 同济大学学士
曾任上市集团产品部负责人(五十余人团队)
多年产品研发及标准化,团队及项目管理经验 · 实现国内外双市场交付 · 超亿元销售额
顶尖学术能力 · T-RO、RSS、ICRA、IROS 及 ICLR、NeurIPS 等顶会顶刊持续产出,多篇最佳论文与荣誉提名
系统级全栈 · 覆盖理解 · 感知 · 规划 · 控制 · 多类机器人 embodiment,从算法研究到整机部署落地的完整链条
同门深耕、默契协作 · 港科Robotics实验室核心团队,多年并肩攻关,团队配合紧密、决策与执行同频
技术研发、战略规划与资源对接
香港科技大学 副教授
国家级人才计划
顶级论文
博士研究生
硕士研究生
2024 IEEE RA-L 最佳论文荣誉提名 · 2025 IEEE ICRA 最佳论文候选
2025 IEEE/RSJ IROS 最佳学生论文候选 · 移动操作最佳论文
担任机器人、自动驾驶等顶级期刊会议编委,并持续培养高水平博士与硕士研究团队。
合作、项目与转化
总项目经费
入选多个国家级、省级科技人才库,核心参与多个国家级重点项目
在机器人、自动驾驶等方向具备核心技术产研转化经验,与华为、理想、广汽、元戎启行、路特斯等头部企业保持深度合作
交互式规划 · 接触丰富的精细操作(principle of contact reasoning)· 移动操作 · 安全运动规划与避障 · 全身安全控制
视觉语言操作 · 开放词汇导航 · 强化学习 · 世界模型
从动作执行层(灵巧、安全的与环境交互)到理解层(人的指令、泛化交互理解),全栈系统经验积累
以交互式运动规划为核心,从自研交互数据范式出发,
训练多模态交互世界模型,搭建从交互意图到动作执行的桥梁
动作意图驱动的隐空间推理预测器将任务导向的场景理解和动作执行层打通,形成从交互信息演化到高动态移动操作任务执行的闭环。
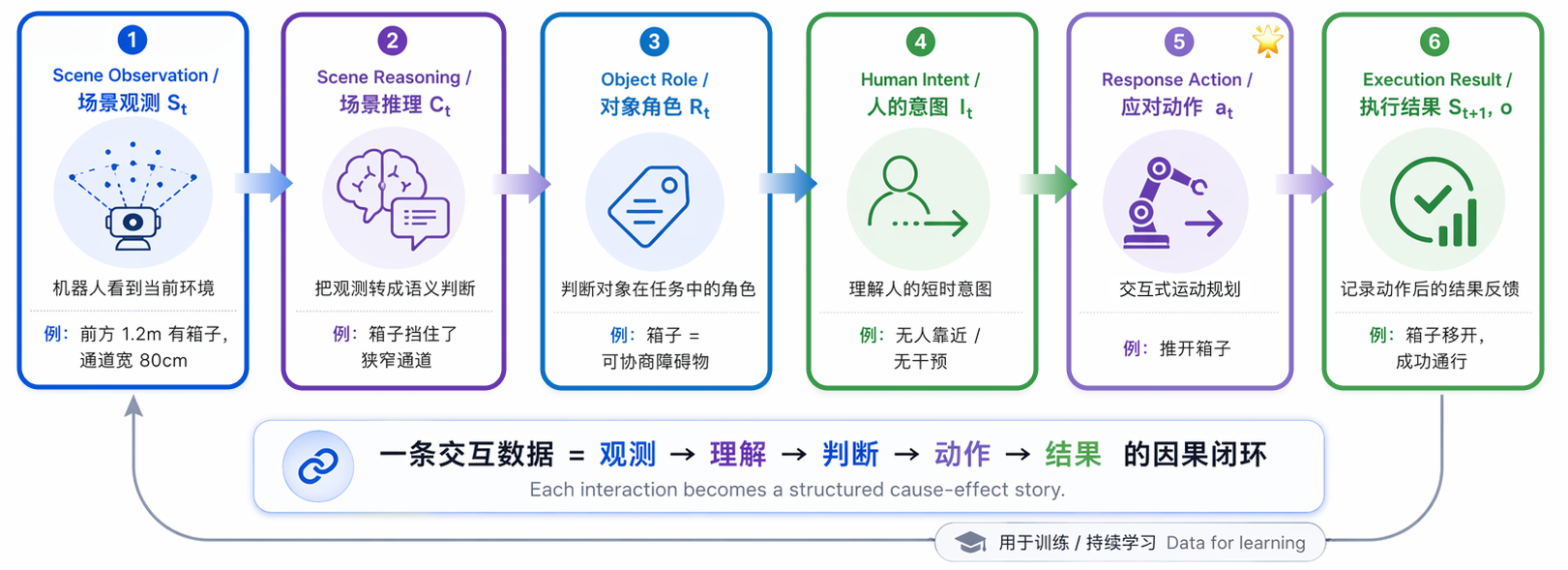
协律科技 核心技术 I
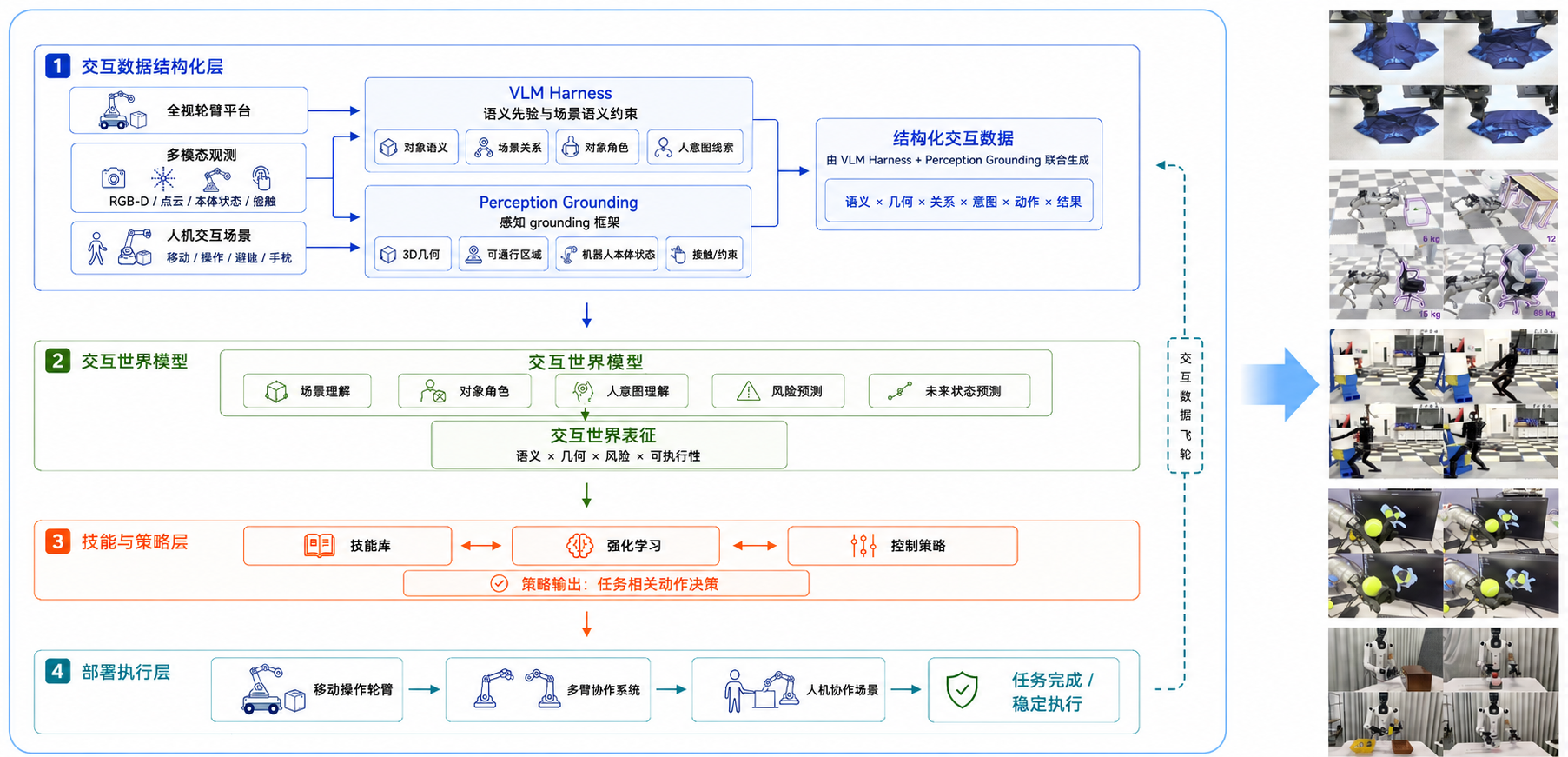
定义结构化交互数据 · 把真实交互转化为可学习的因果样本
把真实交互编码为结构化数据,从环境观测与场景推理,经对象角色与应对动作,闭环于执行结果反馈
以自有交互数据驱动模型学习动作意图下的场景信息演化,实现从场景理解到动作执行的完整闭环
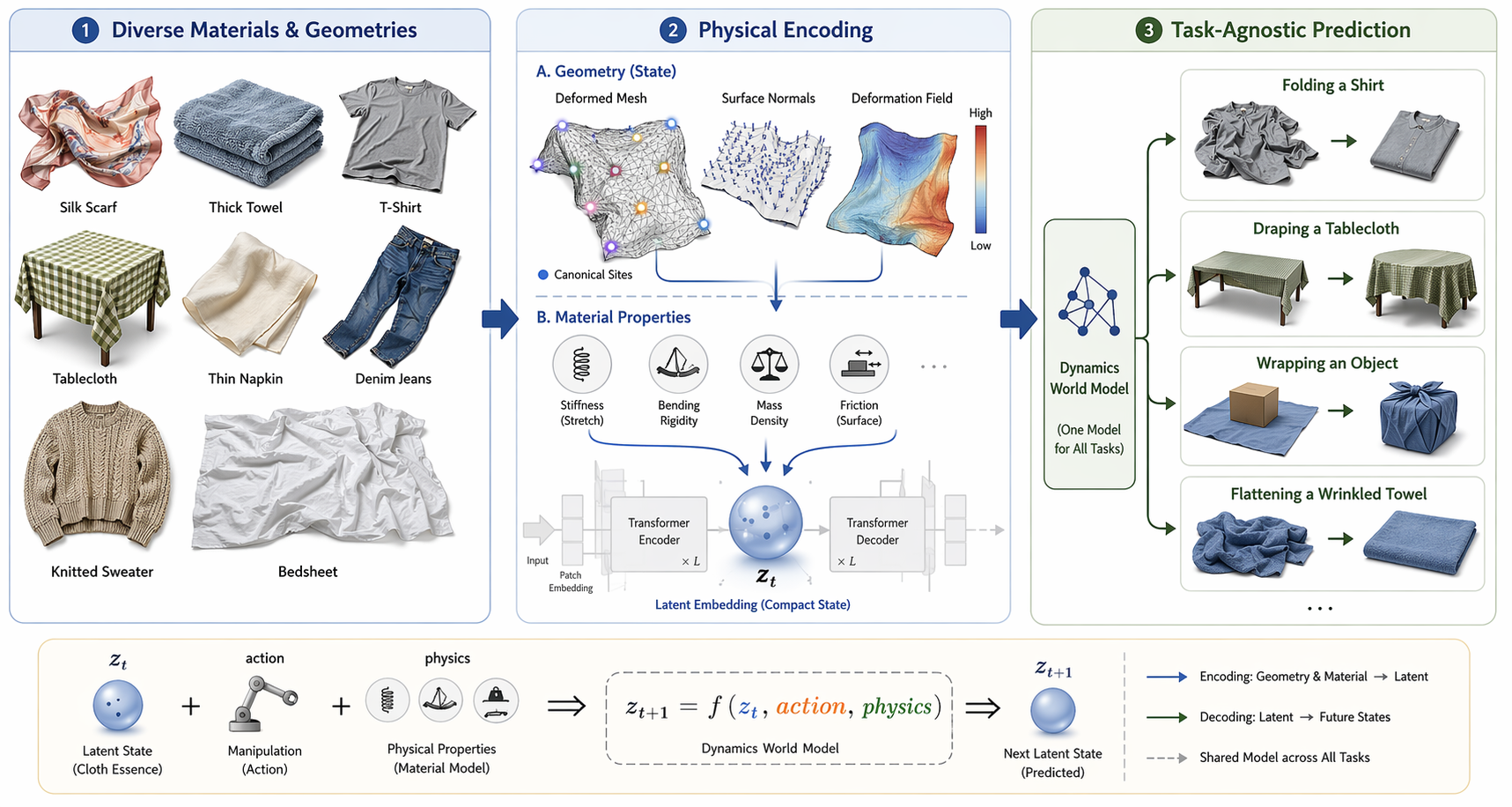
协律科技 核心技术 II
在统一的隐空间中联合交互信息推理动作执行
以布料操作为例:只有当世界模型将布料的材料属性与几何状态编码进潜空间,学会基于物理本质进行推理预测,而非模仿特定动作,才能真正具备跨任务的泛化性潜力。
编码物理本质而非模仿表面行为,是机器人操作泛化性的基础
将“因对象而异的交互规律”编码进模型隐空间,使模型具备机器人动作对交互对象状态变化的因果推理,实现跨交互场景泛化
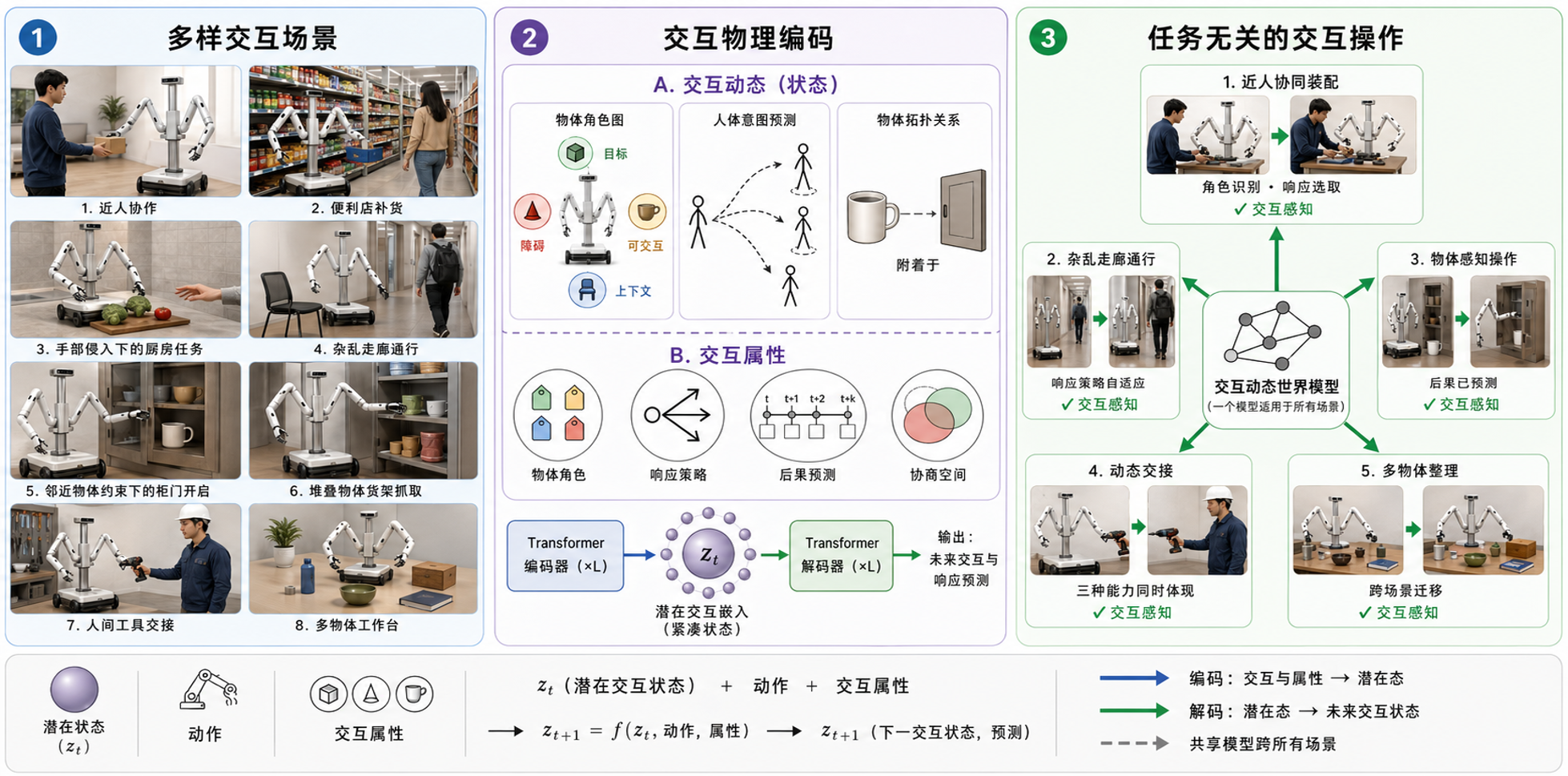
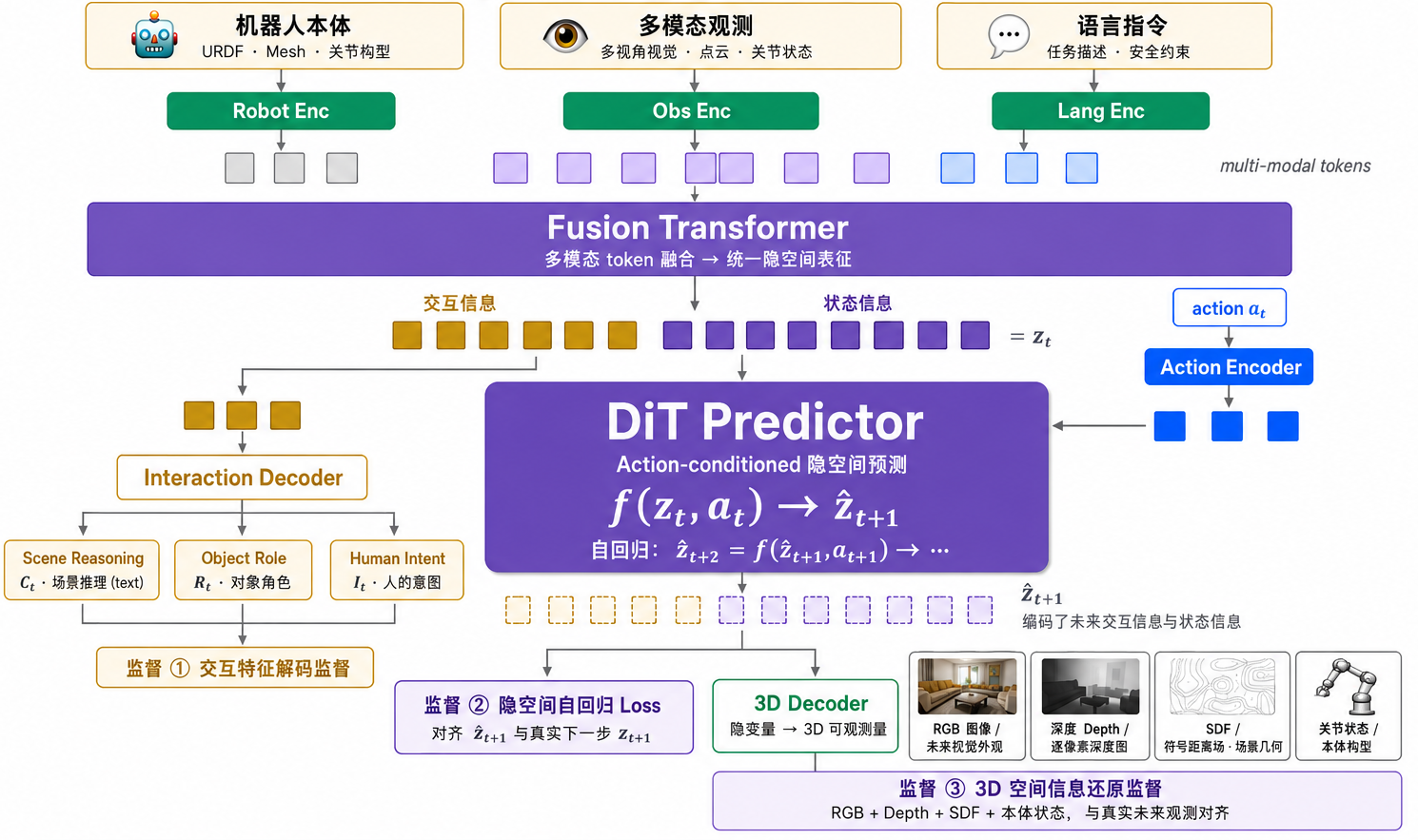
同时预测操作行为引发的环境状态变化与交互信息的演化,具备交互理解能力的操作世界模型。
优先进入零售、连锁两大商业服务场景,逐步泛化开放式高交互场景移动操作能力

全视方案适配高交互场景

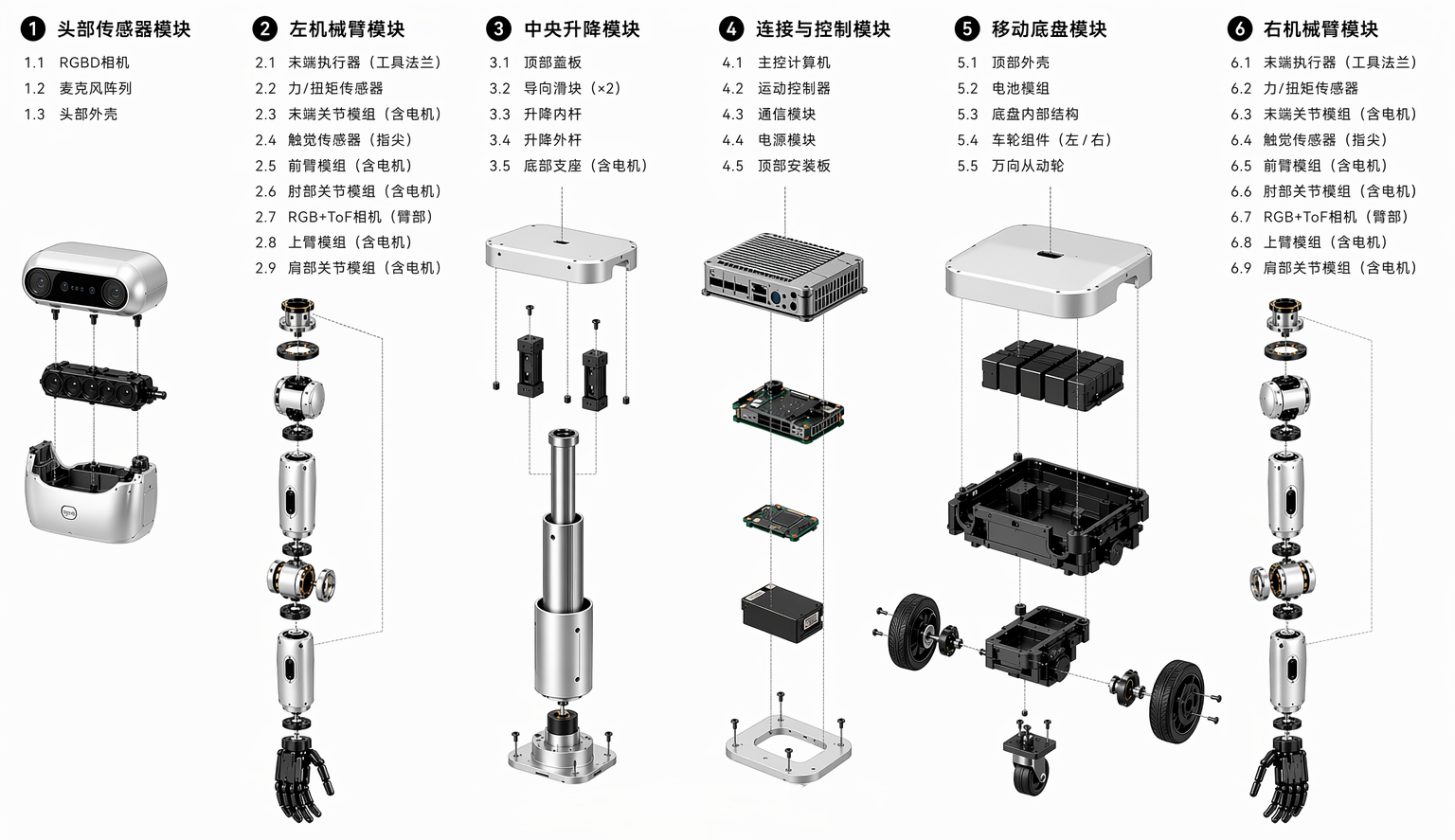
紧凑本体 · 适配近人空间
轮式底盘与双臂紧凑集成,统一调度移动与操作,支持双臂协作。机身适配商超、家居、柜口等受限空间,单体完成完整交互任务。
全视冗余 · 消除交互盲区 · 多模态融合 · 鲁棒于环境变化
传感器围绕操作半径布局,360° 覆盖机器人、目标、人与关联物。多视角视觉 + 点云 + 本体状态交叉验证,消除贴身盲区。
完整观测 · 结构化监督数据
从完整交互观测自动产出高质量监督数据,反哺交互世界模型,形成感知—动作—结果全链路数据。
从本体到数据再到模型,贯通真实交互的完整决策回路